date : 2021-04-03
ImageNet Classification with Deep Convolutional Neural Networks
Abstract
large, deep CNN to classify image into 1000 classes.
Dataset : ImageNet
NN : 5 convolutional layers -> some followed by max-pooling layers -> 3 FC layers -> 1000 way softmax
Make training Faster : 1. non-saturating neurons 2. a very efficient GPU
Reduce Overfitting in FC : employ recently-developed regularization method “dropout”
Introduction
Object Recognition 에 Machine learning methods 사용.
collect larger datasets, learn more powerful models, use better techniques for preventing overfitting.
이전 : datasets of labeled image 가 작았음. 그래서 simple recognition task 는 잘 함. + with label-preserving transforms.
하지만 : objects in realistic settings exhibit considerable variability. => need much larger training sets.
(적은 양의 데이터의 단점 존재.)
ImageNet : 15 millions high-resolution labeled in over 22000 categories.
많은 양의 데이터로부터 몇 천개의 object에 대해 배우려면, need model with large learning capacity.
하지만, Object Recognition Task 는 굉장히 복잡한 작업이기 때문에, ImageNet 데이터셋으로 충분하지 않음.
model 은 데이터셋이 가지지 못한 정보를 보완할 수 있는 많은 사전 지식을 가지고 있어야함.
CNN은 capacity 가 depth 와 breadth 에 의해 조절됨. 그리고 image 의 본질인 stationarity of statistics (픽셀 주변에서 많은 변화가 없음)과 locality of pixel dependencies (neighboring pixels tend to be correlated. far-away pixels usually not correlated.) 에 대한 추측을 강하고 거의 정확하게 함. => 비슷한 사이즈의 feedforward neural network 보다 더 적은 커넥션과 파라미터를 가지고 있어 학습하기 쉽지만 성능은 조금만 떨어짐.
GPU + 최적화된 2D convolution -> 큰 스케일의 CNN 학습시키기 충분.
- network new and unusual features improve performance and reduce training time (section 3)
- overfitting problem -> prevented by several techniques. (section 4)
네트워크 사이즈 - limited mainly by the amount of memory avaliable on current GPUs & the amount of training time we can tolerate.
Dataset
training images, validation images, testing images.
Preprocessing
-
This system required constant input dimensionaliy -> downsampled images to fixed resolution 256x256.
rectangular : rescale shorter side 256 -> crop central 256x256.
-
subtract mean activity over the training set from each pixel (?)
Source : Trained network on the (centered) raw RGB values of the pixels. centered ?
질문사항) normalize image
- Subtract the mean per channel calculated over all images (e.g. VGG_ILSVRC_16_layers)
- Subtract by pixel/channel calculated over all images (e.g. CNN_S, also see Caffe’s reference network)
https://stats.stackexchange.com/questions/211436/why-normalize-images-by-subtracting-datasets-image-mean-instead-of-the-current
data normalization (my search) :
네트워크 학습시킬 때 convergence 빨리 되도록 input parameter 가 similar distribution 갖도록 하는 작업.
참고) https://becominghuman.ai/image-data-pre-processing-for-neural-networks-498289068258
Architecture
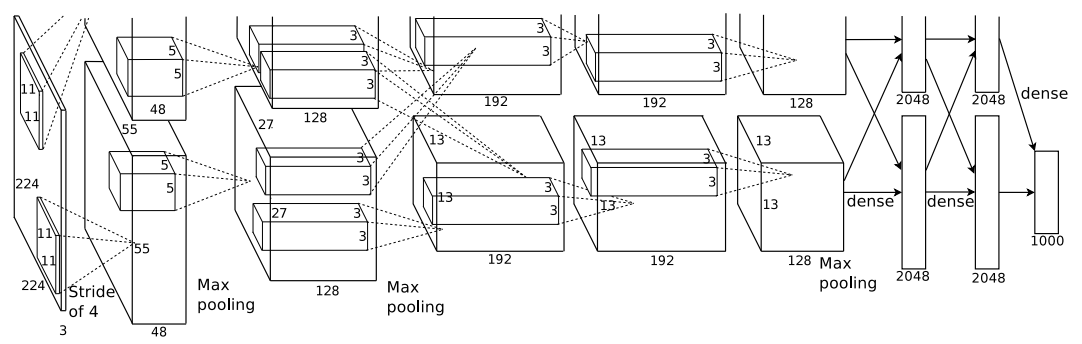
for improving performance and reducing training time
1. ReLU Nonlinearity
예전에는 way to model neuron’s output = saturating-nonlinearity 함수를 써서 training with gradient descent 할 때 오래걸림.
\[f(x) =max(0, x)\]Deep Convolutional neural network train several times faster than traditional units. -> can experiment with such large neural networks. Faster learning
2. Training with multiple GPUs.
spread the net across 2 GPUs. cross-GPU parellelization. + GPUs communicate only in certain layers. otherwise, only get input from same GPU. can choose the pattern of connectivity
take less time to train than using single GPUs.
3. Local Response Normalization
? first sentence. = cannot understand.
local normalization => aids generalization.
식.
apply normalization after applying the ReLU in certain layers.
=> reduce error rates.
4. Overlapping Pooling
reduce error rates. + observe that overfitting 도 살짝 줄여줌.
Reduce Overfitting
1. Data Augmentation
-
- generating image translations and horizontal reflection
-
extracting random 224x224 patches + horizontal reflection
-> use in training
test 할때도 extract 해서 그것들의 평균을 활용하여 예측
-
alternating intensities of the RGB channels in training images.
perform PCA -> add found principal components * eigenvalues * random variable
=> capture important property of natural images (object identity) intensity 와 color of illumination 에 민감하지 않은 것들.
2. Dropout
기존: combining predictions of many different models -> too expensive.
dropout = setting to zero the output of each hidden neuron with probability 0.5
random. -> reduce complex co-adaptation of neurons. cannot rely on the presence of particular other neuron.
applied on first two FC layers.
trained models using stochastic gradient descent.