date: 2022-09-25
This is a review of a paper Very Deep Convolutional Networks for Large-Scale Image Recognition (2014).
The meaning of this paper can be defined in two ways.
-
only using 3x3 conv filters and stacking them deeply
-
Doubling the # of channels of conv layers after max pooling (width/height of the feature map becomes half the size)
1. only using 3x3 conv filters and stacking them deeply
There were many efforts to make convolutional neural network deeper.
But, the VGGNet was successful in that it used only 3x3 convolution filters in stacking the convolutional layers.
Stacking 3x3 convolution filter repetitively has the effect of having larger receptive fields like the effect of using 5x5 or 7x7 convolution filters.
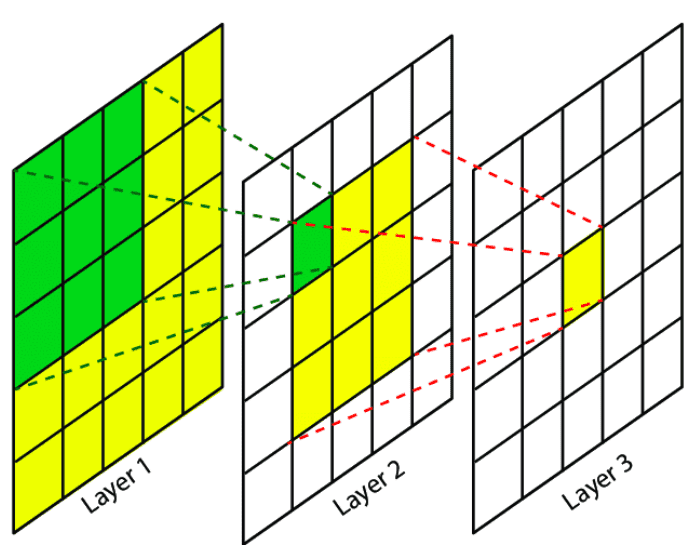
Image Source: Research Gate
Meaning of having Large Receptive Field
Receptive field (RF) is defined as the size of the region in the input that produces the feature. [1]
The idea of receptive field applies to local operations (convolution, pooling).
Example 1.
In image segmentation and optical flow estimation, we produce a prediction for each pixel in the input image, which corresponds to semantic label map. The larger the receptive field, the better, because we can ensure that no crucial information was not taken into account.
Example 2.
Also, in object detection, a small receptive field may not be able to recognize large objects.
Therefore, it is ideal to design a convolutional model so that we can ensure that RF covers the entire relevant input image region.
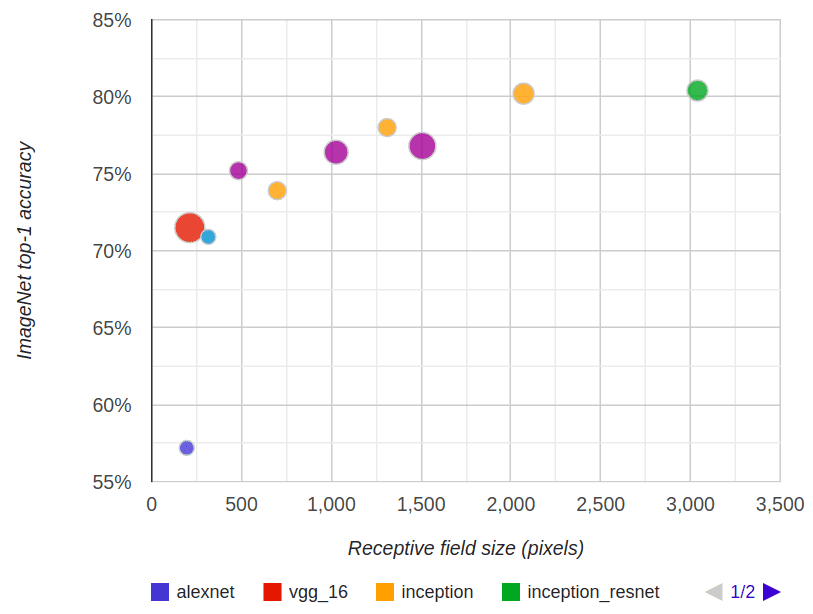
In fact, a logarithmic relationship between classification accuracy and receptive field size is observed by [1], which confirms that large receptive fields are necessary for high-level recognition tasks, but with diminishing rewards.
Source : [2], Image Source : [1]
Benefits of using multiple 3x3 filter rather than single large filter
There are two benefits of using only 3x3 convolution filter and repetitvely.
-
One is that by using multiple number of convolution layer, we can incorporate more non-linear layers (ex. ReLU) to this model.
Incorporating more activation functions into this model makes the decision function more discriminative.
-
Another is that we can decrease the number of parameters of the model.
The benefit of having smaller number of parameter is that the amount of computation can be smaller. Thus, memory consumption can be smaller than usual. Also, we can avoid overfitting problem by not having so many parameters. ?
reference link for calculating # of parameters
2. Doubling the # of channels of conv layers after max pooling
Meaning of this behavior
It compensates the width and height being half the size after non-overlapping max pooling.
This enables to detect richer features.
Downside of VGGNet
There are too many parameters in VGGNet.
This is due to FC layer, which is at the end of convolution layers, and the convolutional layers whose number of channels are too large when compared to the resolution of their input image (ex. conv3-512).
VGG16 implemented in CUDA
This is the code for vgg-16 net implemented in CUDA.
#include "vgg16_cuda.h"
#include <cmath>
#include <iostream>
#define TILE_WIDTH 2
void vgg16_cuda::predict(int batch) {
gpu_normalize(d_image, d_input);
//////////BLOCK 1/////////////////////////////////
// ZeroPad2d
gpu_pad(d_input, d_input_padded, batch, input_channel, input_size, input_size, conv1_1_padding_size);
// Conv2d
gpu_conv(d_input_padded, d_C1_1_feature_map, d_conv1_1_weight, d_conv1_1_bias, batch, input_size+2*conv1_1_padding_size,
input_size+2*conv1_1_padding_size, conv1_1_in_channel, conv1_1_out_channel, conv1_1_kernel_size);
gpu_relu(d_C1_1_feature_map, batch * C1_1_channel * C1_1_size * C1_1_size);
// ZeroPad2d
gpu_pad(d_C1_1_feature_map, d_C1_1_feature_map_padded, batch, C1_1_channel, C1_1_size, C1_1_size, conv1_2_padding_size);
gpu_conv(d_C1_1_feature_map_padded, d_C1_2_feature_map, d_conv1_2_weight, d_conv1_2_bias, batch, C1_1_size+2*conv1_2_padding_size,
C1_1_size+2*conv1_2_padding_size, conv1_2_in_channel, conv1_2_out_channel, conv1_2_kernel_size);
gpu_relu(d_C1_2_feature_map, batch * C1_2_channel * C1_2_size * C1_2_size);
gpu_pool(d_C1_2_feature_map, d_S1_feature_map, batch, C1_2_channel, C1_2_size, C1_2_size);
//////////BLOCK 2/////////////////////////////////
gpu_pad(d_S1_feature_map, d_S1_feature_map_padded, batch, S1_channel, S1_size, S1_size, conv2_1_padding_size);
gpu_conv(d_S1_feature_map_padded, d_C2_1_feature_map, d_conv2_1_weight, d_conv2_1_bias, batch, S1_size+2*conv2_1_padding_size,
S1_size+2*conv2_1_padding_size, conv2_1_in_channel, conv2_1_out_channel, conv2_1_kernel_size);
gpu_relu(d_C2_1_feature_map, batch * C2_1_channel * C2_1_size * C2_1_size);
gpu_pad(d_C2_1_feature_map, d_C2_1_feature_map_padded, batch, C2_1_channel, C2_1_size, C2_1_size, conv2_2_padding_size);
gpu_conv(d_C2_1_feature_map_padded, d_C2_2_feature_map, d_conv2_2_weight, d_conv2_2_bias, batch, C2_1_size+2*conv2_2_padding_size,
C2_1_size+2*conv2_2_padding_size, conv2_2_in_channel, conv2_2_out_channel, conv2_2_kernel_size);
gpu_relu(d_C2_2_feature_map, batch * C2_2_channel * C2_2_size * C2_2_size);
gpu_pool(d_C2_2_feature_map, d_S2_feature_map, batch, C2_2_channel, C2_2_size, C2_2_size);
//////////BLOCK 3/////////////////////////////////
gpu_pad(d_S2_feature_map, d_S2_feature_map_padded, batch, S2_channel, S2_size, S2_size, conv3_1_padding_size);
gpu_conv(d_S2_feature_map_padded, d_C3_1_feature_map, d_conv3_1_weight, d_conv3_1_bias, batch, S2_size+2*conv3_1_padding_size,
S2_size+2*conv3_1_padding_size, conv3_1_in_channel, conv3_1_out_channel, conv3_1_kernel_size);
gpu_relu(d_C3_1_feature_map, batch * C3_1_channel * C3_1_size * C3_1_size);
gpu_pad(d_C3_1_feature_map, d_C3_1_feature_map_padded, batch, C3_1_channel, C3_1_size, C3_1_size, conv3_2_padding_size);
gpu_conv(d_C3_1_feature_map_padded, d_C3_2_feature_map, d_conv3_2_weight, d_conv3_2_bias, batch, C3_1_size+2*conv3_2_padding_size,
C3_1_size+2*conv3_2_padding_size, conv3_2_in_channel, conv3_2_out_channel, conv3_2_kernel_size);
gpu_relu(d_C3_2_feature_map, batch * C3_2_channel * C3_2_size * C3_2_size);
// ZeroPad2d
gpu_pad(d_C3_2_feature_map, d_C3_2_feature_map_padded, batch, C3_2_channel, C3_2_size, C3_2_size, conv3_3_padding_size);
// conv2d
gpu_conv(d_C3_2_feature_map_padded, d_C3_3_feature_map, d_conv3_3_weight, d_conv3_3_bias, batch, C3_2_size+2*conv3_3_padding_size,
C3_2_size+2*conv3_3_padding_size, conv3_3_in_channel, conv3_3_out_channel, conv3_3_kernel_size);
gpu_relu(d_C3_3_feature_map, batch * C3_3_channel * C3_3_size * C3_3_size);
// MaxPool2d
gpu_pool(d_C3_3_feature_map, d_S3_feature_map, batch, C3_3_channel, C3_3_size, C3_3_size);
//////////BLOCK 4/////////////////////////////////
// ZeroPad2d
gpu_pad(d_S3_feature_map, d_S3_feature_map_padded, batch, S3_channel, S3_size, S3_size, conv4_1_padding_size);
// conv2d
gpu_conv(d_S3_feature_map_padded, d_C4_1_feature_map, d_conv4_1_weight, d_conv4_1_bias, batch, S3_size+2*conv4_1_padding_size,
S3_size+2*conv4_1_padding_size, conv4_1_in_channel, conv4_1_out_channel, conv4_1_kernel_size);
gpu_relu(d_C4_1_feature_map, batch * C4_1_channel * C4_1_size * C4_1_size);
// ZeroPad2d
gpu_pad(d_C4_1_feature_map, d_C4_1_feature_map_padded, batch, C4_1_channel, C4_1_size, C4_1_size, conv4_2_padding_size);
// conv2d
gpu_conv(d_C4_1_feature_map_padded, d_C4_2_feature_map, d_conv4_2_weight, d_conv4_2_bias, batch, C4_1_size+2*conv4_2_padding_size,
C4_1_size+2*conv4_2_padding_size, conv4_2_in_channel, conv4_2_out_channel, conv4_2_kernel_size);
gpu_relu(d_C4_2_feature_map, batch * C4_2_channel * C4_2_size * C4_2_size);
// ZeroPad2d
gpu_pad(d_C4_2_feature_map, d_C4_2_feature_map_padded, batch, C4_2_channel, C4_2_size, C4_2_size, conv4_3_padding_size);
// conv2d
gpu_conv(d_C4_2_feature_map_padded, d_C4_3_feature_map, d_conv4_3_weight, d_conv4_3_bias, batch, C4_2_size+2*conv4_3_padding_size,
C4_2_size+2*conv4_3_padding_size, conv4_3_in_channel, conv4_3_out_channel, conv4_3_kernel_size);
gpu_relu(d_C4_3_feature_map, batch * C4_3_channel * C4_3_size * C4_3_size);
// MaxPool2d
gpu_pool(d_C4_3_feature_map, d_S4_feature_map, batch, C4_3_channel, C4_3_size, C4_3_size);
//////////BLOCK 5/////////////////////////////////
// ZeroPad2d
gpu_pad(d_S4_feature_map, d_S4_feature_map_padded, batch, S4_channel, S4_size, S4_size, conv5_1_padding_size);
// conv2d
gpu_conv(d_S4_feature_map_padded, d_C5_1_feature_map, d_conv5_1_weight, d_conv5_1_bias, batch, S4_size+2*conv5_1_padding_size,
S4_size+2*conv5_1_padding_size, conv5_1_in_channel, conv5_1_out_channel, conv5_1_kernel_size);
gpu_relu(d_C5_1_feature_map, batch * C5_1_channel * C5_1_size * C5_1_size);
// ZeroPad2d
gpu_pad(d_C5_1_feature_map, d_C5_1_feature_map_padded, batch, C5_1_channel, C5_1_size, C5_1_size, conv5_2_padding_size);
// conv2d
gpu_conv(d_C5_1_feature_map_padded, d_C5_2_feature_map, d_conv5_2_weight, d_conv5_2_bias, batch, C5_1_size+2*conv5_2_padding_size,
C5_1_size+2*conv5_2_padding_size, conv5_2_in_channel, conv5_2_out_channel, conv5_2_kernel_size);
gpu_relu(d_C5_2_feature_map, batch * C5_2_channel * C5_2_size * C5_2_size);
// ZeroPad2d
gpu_pad(d_C5_2_feature_map, d_C5_2_feature_map_padded, batch, C5_2_channel, C5_2_size, C5_2_size, conv5_3_padding_size);
// conv2d
gpu_conv(d_C5_2_feature_map_padded, d_C5_3_feature_map, d_conv5_3_weight, d_conv5_3_bias, batch, C5_2_size+2*conv5_3_padding_size,
C5_2_size+2*conv5_3_padding_size, conv5_3_in_channel, conv5_3_out_channel, conv5_3_kernel_size);
gpu_relu(d_C5_3_feature_map, batch * C5_3_channel * C5_3_size * C5_3_size);
// MaxPool2d
gpu_pool(d_C5_3_feature_map, d_S5_feature_map, batch, C5_3_channel, C5_3_size, C5_3_size);
// Linear
gpu_fc(d_S5_feature_map, d_output, d_fc1_weight, d_fc1_bias, batch, fc1_in_channel,
fc1_out_channel);
/* NOTE: unless you want to make a major change to this class structure,
* you need to write your output to the device memory d_output
* so that classify() can handle the rest.
*/
}
__global__ void normal_kernel(const uint8_t* const image, float* input, int n){
// Initialize variables
float max_int = 255.0L;
float mean = 0.5L;
float var = 0.5L;
int i = threadIdx.x + blockDim.x * blockIdx.x;
// normalize
if (i < n){
input[i] = image[i] / max_int; // transforms.ToTensor();
input[i] = (input[i] - mean) / var; // transforms.Normalize();
}
}
void vgg16_cuda::gpu_normalize(const uint8_t* const image, float* input){
int num_blocks = ceil(batch*input_channel*input_size*input_size/1024.0);
int block_size = 1024;
normal_kernel<<<num_blocks, block_size>>>(image, input, batch*input_channel*input_size*input_size);
}
__global__ void relu_kernel(float* feature_map, int size){
int i = threadIdx.x + blockDim.x * blockIdx.x;
if (i < size){
if (feature_map[i] < 0.0){feature_map[i] = 0.0;}
}
}
void vgg16_cuda::gpu_relu(float* feature_map, int size){
int num_blocks = ceil(size/1024.0);
int block_size = 1024;
relu_kernel<<<num_blocks, block_size>>>(feature_map, size);
}
__global__ void pad_kernel(float* input, float* input_padded,
int B, int C, int H, int W, int P){
int H_OUT = H+2*P;
int W_OUT = W+2*P;
// int W_grid = W / TILE_WIDTH;
int b = blockIdx.x;
int h = threadIdx.x;
int c,w;
c = blockIdx.y;
w = threadIdx.y;
int input_base = b * (C * H * W) + c * (H * W) + h * (W) + w;
// Set output with max value
int output_index = b * (C * H_OUT * W_OUT) + c * (H_OUT * W_OUT) +
(h+P) * W_OUT + (w + P);
input_padded[output_index] = input[input_base];
}
void vgg16_cuda::gpu_pad(float* input, float* input_padded,
int B, int C, int H, int W, int P){
dim3 gridDim(B,C,1);
dim3 blockDim(H,W,1);
pad_kernel<<<gridDim, blockDim>>>(input, input_padded, B, C, H, W, P);
}
__global__ void conv_kernel(float* input, float* output, float* weight, float* bias,
int B, int H, int W, int IC, int OC, int K){
int H_OUT = H - (K - 1);
int W_OUT = W - (K - 1);
int b = blockIdx.x;
int oc = blockIdx.y;
int h = threadIdx.x;
int w = threadIdx.y;
int output_index =
b * (OC * H_OUT * W_OUT) + oc * (H_OUT * W_OUT) + h * W_OUT + w;
// output[output_index] = bias[oc];
float total_sum = 0;
for (int ic = 0; ic < IC; ic++) {
int input_base = b * (IC * H * W) + ic * (H * W) + h * (W) + w;
int kernel_base = oc * (IC * K * K) + ic * (K * K);
total_sum += input[input_base] * weight[kernel_base] +
input[input_base+1]*weight[kernel_base+1]+
input[input_base+2]*weight[kernel_base+2]+
input[input_base+W]*weight[kernel_base+K]+
input[input_base+W+1]*weight[kernel_base+K+1]+
input[input_base+W+2]*weight[kernel_base+K+2]+
input[input_base+2*W]*weight[kernel_base+2*K]+
input[input_base+2*W+1]*weight[kernel_base+2*K+1]+
input[input_base+2*W+2]*weight[kernel_base+2*K+2];
}
output[output_index] = total_sum + bias[oc];
}
void vgg16_cuda::gpu_conv(float* input, float* output, float* weight, float* bias,
int B, int H, int W, int IC, int OC, int K){
// Initialize variable
int H_OUT = H - (K - 1);
int W_OUT = W - (K - 1);
dim3 gridDim(B,OC,1);
dim3 blockDim(H_OUT,W_OUT,1);
conv_kernel<<<gridDim, blockDim>>>(input, output, weight, bias,
B, H, W, IC, OC, K);
}
__global__ void pool_kernel(float* input, float* output,
int B, int C, int H, int W, float Max_val, float Epsilon){
// Init values
int scale = 2;
int H_OUT = H / scale;
int W_OUT = W / scale;
int b = blockIdx.x;
int c = blockIdx.y;
int h = threadIdx.x;
int w = threadIdx.y;
if ((h%scale!= 0)||(w%scale!= 0)){return;}
int input_base = b * (C * H * W) + c * (H * W) + h * (W) + w;
float max_val = Max_val;
// Find maximum
float fir_max = (input[input_base] > input[input_base+1]+Epsilon)? input[input_base]:input[input_base+1];
float sec_max = (input[input_base+W] > input[input_base+W+1]+Epsilon)? input[input_base+W] : input[input_base+W+1];
float max = (fir_max > sec_max+Epsilon)? fir_max:sec_max;
max_val = (max_val > max + Epsilon) ? max_val:max;
// Set output with max value
int output_index = b * (C * H_OUT * W_OUT) + c * (H_OUT * W_OUT) +
(h / scale) * W_OUT + (w / scale);
output[output_index] = max_val;
}
void vgg16_cuda::gpu_pool(float* input, float* output,
int B, int C, int H, int W){
// Initialize variable
dim3 gridDim(B,C,1);
dim3 blockDim(H,W,1);
float max_val = std::numeric_limits<float>::lowest();
float epsilon = std::numeric_limits<float>::epsilon();
pool_kernel<<<gridDim, blockDim>>>(input, output, B, C, H, W, max_val, epsilon);
}
__global__ void fc_kernel(float* input, float* output, float* weight, float* bias,
int B, int IC, int OC){
int b = threadIdx.x;
int oc = blockIdx.x;
float sum = 0.0;
for (int ic = 0; ic < IC; ic++)
sum += weight[oc * IC + ic] * input[b * IC + ic];
output[b*OC + oc] = bias[oc] + sum;
}
void vgg16_cuda::gpu_fc(float* input, float* output, float* weight, float* bias,
int B, int IC, int OC){
dim3 dimGrid(OC,1,1);
dim3 dimBlock(B, 1, 1);
fc_kernel<<<dimGrid, dimBlock>>>(input, output, weight, bias, B, IC, OC);
}
void vgg16_cuda::prepare_device_memory(uint8_t* image) {
// Alloc Model Parameters
//////////BLOCK 1/////////////////////////////////
cudaMalloc((void**)&d_conv1_1_weight,
sizeof(float) * conv1_1_in_channel * conv1_1_out_channel *
conv1_1_kernel_size * conv1_1_kernel_size);
cudaMalloc((void**)&d_conv1_1_bias, sizeof(float) * conv1_1_out_channel);
cudaMalloc((void**)&d_conv1_2_weight,
sizeof(float) * conv1_2_in_channel * conv1_2_out_channel *
conv1_2_kernel_size * conv1_2_kernel_size);
cudaMalloc((void**)&d_conv1_2_bias, sizeof(float) * conv1_2_out_channel);
//////////BLOCK 2/////////////////////////////////
cudaMalloc((void**)&d_conv2_1_weight,
sizeof(float) * conv2_1_in_channel * conv2_1_out_channel *
conv2_1_kernel_size * conv2_1_kernel_size);
cudaMalloc((void**)&d_conv2_1_bias, sizeof(float) * conv2_1_out_channel);
cudaMalloc((void**)&d_conv2_2_weight,
sizeof(float) * conv2_2_in_channel * conv2_2_out_channel *
conv2_2_kernel_size * conv2_2_kernel_size);
cudaMalloc((void**)&d_conv2_2_bias, sizeof(float) * conv2_2_out_channel);
//////////BLOCK 3/////////////////////////////////
cudaMalloc((void**)&d_conv3_1_weight,
sizeof(float) * conv3_1_in_channel * conv3_1_out_channel *
conv3_1_kernel_size * conv3_1_kernel_size);
cudaMalloc((void**)&d_conv3_1_bias, sizeof(float) * conv3_1_out_channel);
cudaMalloc((void**)&d_conv3_2_weight,
sizeof(float) * conv3_2_in_channel * conv3_2_out_channel *
conv3_2_kernel_size * conv3_2_kernel_size);
cudaMalloc((void**)&d_conv3_2_bias, sizeof(float) * conv3_2_out_channel);
cudaMalloc((void**)&d_conv3_3_weight,
sizeof(float) * conv3_3_in_channel * conv3_3_out_channel *
conv3_3_kernel_size * conv3_3_kernel_size);
cudaMalloc((void**)&d_conv3_3_bias, sizeof(float) * conv3_3_out_channel);
//////////BLOCK 4/////////////////////////////////
cudaMalloc((void**)&d_conv4_1_weight,
sizeof(float) * conv4_1_in_channel * conv4_1_out_channel *
conv4_1_kernel_size * conv4_1_kernel_size);
cudaMalloc((void**)&d_conv4_1_bias, sizeof(float) * conv4_1_out_channel);
cudaMalloc((void**)&d_conv4_2_weight,
sizeof(float) * conv4_2_in_channel * conv4_2_out_channel *
conv4_2_kernel_size * conv4_2_kernel_size);
cudaMalloc((void**)&d_conv4_2_bias, sizeof(float) * conv4_2_out_channel);
cudaMalloc((void**)&d_conv4_3_weight,
sizeof(float) * conv4_3_in_channel * conv4_3_out_channel *
conv4_3_kernel_size * conv4_3_kernel_size);
cudaMalloc((void**)&d_conv4_3_bias, sizeof(float) * conv4_3_out_channel);
//////////BLOCK 5/////////////////////////////////
cudaMalloc((void**)&d_conv5_1_weight,
sizeof(float) * conv5_1_in_channel * conv5_1_out_channel *
conv5_1_kernel_size * conv5_1_kernel_size);
cudaMalloc((void**)&d_conv5_1_bias, sizeof(float) * conv5_1_out_channel);
cudaMalloc((void**)&d_conv5_2_weight,
sizeof(float) * conv5_2_in_channel * conv5_2_out_channel *
conv5_2_kernel_size * conv5_2_kernel_size);
cudaMalloc((void**)&d_conv5_2_bias, sizeof(float) * conv5_2_out_channel);
cudaMalloc((void**)&d_conv5_3_weight,
sizeof(float) * conv5_3_in_channel * conv5_3_out_channel *
conv5_3_kernel_size * conv5_3_kernel_size);
cudaMalloc((void**)&d_conv5_3_bias, sizeof(float) * conv5_3_out_channel);
//////////FC 1////////////////////////////////////
cudaMalloc((void**)&d_fc1_weight,
sizeof(float) * fc1_in_channel * fc1_out_channel);
cudaMalloc((void**)&d_fc1_bias, sizeof(float) * fc1_out_channel);
// Alloc Activations
cudaMalloc((void**)&d_image,
sizeof(uint8_t) * batch * input_size * input_size * input_channel);
cudaMalloc((void**)&d_input,
sizeof(float) * batch * input_channel * input_size * input_size);
//////////BLOCK 1/////////////////////////////////
cudaMalloc((void**)&d_input_padded,
sizeof(float) * batch * input_channel * (input_size+2*conv1_1_padding_size) * (input_size+2*conv1_1_padding_size));
cudaMalloc((void**)&d_C1_1_feature_map,
sizeof(float) * batch * C1_1_channel * C1_1_size * C1_1_size);
cudaMalloc((void**)&d_C1_1_feature_map_padded,
sizeof(float) * batch * C1_1_channel * (C1_1_size+2*conv1_2_padding_size) * (C1_1_size+2*conv1_2_padding_size));
cudaMalloc((void**)&d_C1_2_feature_map,
sizeof(float) * batch * C1_2_channel * C1_2_size * C1_2_size);
cudaMalloc((void**)&d_S1_feature_map,
sizeof(float) * batch * S1_channel * S1_size * S1_size);
//////////BLOCK 2/////////////////////////////////
cudaMalloc((void**)&d_S1_feature_map_padded,
sizeof(float) * batch * S1_channel * (S1_size+2*conv2_1_padding_size) * (S1_size+2*conv2_1_padding_size));
cudaMalloc((void**)&d_C2_1_feature_map,
sizeof(float) * batch * C2_1_channel * C2_1_size * C2_1_size);
cudaMalloc((void**)&d_C2_1_feature_map_padded,
sizeof(float) * batch * C2_1_channel * (C2_1_size+2*conv2_2_padding_size) * (C2_1_size+2*conv2_2_padding_size));
cudaMalloc((void**)&d_C2_2_feature_map,
sizeof(float) * batch * C2_2_channel * C2_2_size * C2_2_size);
cudaMalloc((void**)&d_S2_feature_map,
sizeof(float) * batch * S2_channel * S2_size * S2_size);
//////////BLOCK 3/////////////////////////////////
cudaMalloc((void**)&d_S2_feature_map_padded,
sizeof(float) * batch * S2_channel * (S2_size+2*conv3_1_padding_size) * (S2_size+2*conv3_1_padding_size));
cudaMalloc((void**)&d_C3_1_feature_map,
sizeof(float) * batch * C3_1_channel * C3_1_size * C3_1_size);
cudaMalloc((void**)&d_C3_1_feature_map_padded,
sizeof(float) * batch * C3_1_channel * (C3_1_size+2*conv3_2_padding_size) * (C3_1_size+2*conv3_2_padding_size));
cudaMalloc((void**)&d_C3_2_feature_map,
sizeof(float) * batch * C3_2_channel * C3_2_size * C3_2_size);
cudaMalloc((void**)&d_C3_2_feature_map_padded,
sizeof(float) * batch * C3_2_channel * (C3_2_size+2*conv3_3_padding_size) * (C3_2_size+2*conv3_3_padding_size));
cudaMalloc((void**)&d_C3_3_feature_map,
sizeof(float) * batch * C3_3_channel * C3_3_size * C3_3_size);
cudaMalloc((void**)&d_S3_feature_map,
sizeof(float) * batch * S3_channel * S3_size * S3_size);
//////////BLOCK 4/////////////////////////////////
cudaMalloc((void**)&d_S3_feature_map_padded,
sizeof(float) * batch * S3_channel * (S3_size+2*conv4_1_padding_size) * (S3_size+2*conv4_1_padding_size));
cudaMalloc((void**)&d_C4_1_feature_map,
sizeof(float) * batch * C4_1_channel * C4_1_size * C4_1_size);
cudaMalloc((void**)&d_C4_1_feature_map_padded,
sizeof(float) * batch * C4_1_channel * (C4_1_size+2*conv4_2_padding_size) * (C4_1_size+2*conv4_2_padding_size));
cudaMalloc((void**)&d_C4_2_feature_map,
sizeof(float) * batch * C4_2_channel * C4_2_size * C4_2_size);
cudaMalloc((void**)&d_C4_2_feature_map_padded,
sizeof(float) * batch * C4_2_channel * (C4_2_size+2*conv4_3_padding_size) * (C4_2_size+2*conv4_3_padding_size));
cudaMalloc((void**)&d_C4_3_feature_map,
sizeof(float) * batch * C4_3_channel * C4_3_size * C4_3_size);
cudaMalloc((void**)&d_S4_feature_map,
sizeof(float) * batch * S4_channel * S4_size * S4_size);
//////////BLOCK 5/////////////////////////////////
cudaMalloc((void**)&d_S4_feature_map_padded,
sizeof(float) * batch * S4_channel * (S4_size+2*conv5_1_padding_size) * (S4_size+2*conv5_1_padding_size));
cudaMalloc((void**)&d_C5_1_feature_map,
sizeof(float) * batch * C5_1_channel * C5_1_size * C5_1_size);
cudaMalloc((void**)&d_C5_1_feature_map_padded,
sizeof(float) * batch * C5_1_channel * (C5_1_size+2*conv5_2_padding_size) * (C5_1_size+2*conv5_2_padding_size));
cudaMalloc((void**)&d_C5_2_feature_map,
sizeof(float) * batch * C5_2_channel * C5_2_size * C5_2_size);
cudaMalloc((void**)&d_C5_2_feature_map_padded,
sizeof(float) * batch * C5_2_channel * (C5_2_size+2*conv5_3_padding_size) * (C5_2_size+2*conv5_3_padding_size));
cudaMalloc((void**)&d_C5_3_feature_map,
sizeof(float) * batch * C5_3_channel * C5_3_size * C5_3_size);
cudaMalloc((void**)&d_S5_feature_map,
sizeof(float) * batch * S5_channel * S5_size * S5_size);
cudaMalloc((void**)&d_output, sizeof(float) * batch * output_size);
// Copy Parameters
//////////BLOCK 1/////////////////////////////////
cudaMemcpy(d_conv1_1_weight, conv1_1_weight,
sizeof(float) * conv1_1_in_channel * conv1_1_out_channel *
conv1_1_kernel_size * conv1_1_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv1_1_bias, conv1_1_bias, sizeof(float) * conv1_1_out_channel,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv1_2_weight, conv1_2_weight,
sizeof(float) * conv1_2_in_channel * conv1_2_out_channel *
conv1_2_kernel_size * conv1_2_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv1_2_bias, conv1_2_bias, sizeof(float) * conv1_2_out_channel,
cudaMemcpyHostToDevice);
//////////BLOCK 2/////////////////////////////////
cudaMemcpy(d_conv2_1_weight, conv2_1_weight,
sizeof(float) * conv2_1_in_channel * conv2_1_out_channel *
conv2_1_kernel_size * conv2_1_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv2_1_bias, conv2_1_bias, sizeof(float) * conv2_1_out_channel,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv2_2_weight, conv2_2_weight,
sizeof(float) * conv2_2_in_channel * conv2_2_out_channel *
conv2_2_kernel_size * conv2_2_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv2_2_bias, conv2_2_bias, sizeof(float) * conv2_2_out_channel,
cudaMemcpyHostToDevice);
//////////BLOCK 3/////////////////////////////////
cudaMemcpy(d_conv3_1_weight, conv3_1_weight,
sizeof(float) * conv3_1_in_channel * conv3_1_out_channel *
conv3_1_kernel_size * conv3_1_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv3_1_bias, conv3_1_bias, sizeof(float) * conv3_1_out_channel,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv3_2_weight, conv3_2_weight,
sizeof(float) * conv3_2_in_channel * conv3_2_out_channel *
conv3_2_kernel_size * conv3_2_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv3_2_bias, conv3_2_bias, sizeof(float) * conv3_2_out_channel,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv3_3_weight, conv3_3_weight,
sizeof(float) * conv3_3_in_channel * conv3_3_out_channel *
conv3_3_kernel_size * conv3_3_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv3_3_bias, conv3_3_bias, sizeof(float) * conv3_3_out_channel,
cudaMemcpyHostToDevice);
//////////BLOCK 4/////////////////////////////////
cudaMemcpy(d_conv4_1_weight, conv4_1_weight,
sizeof(float) * conv4_1_in_channel * conv4_1_out_channel *
conv4_1_kernel_size * conv4_1_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv4_1_bias, conv4_1_bias, sizeof(float) * conv4_1_out_channel,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv4_2_weight, conv4_2_weight,
sizeof(float) * conv4_2_in_channel * conv4_2_out_channel *
conv4_2_kernel_size * conv4_2_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv4_2_bias, conv4_2_bias, sizeof(float) * conv4_2_out_channel,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv4_3_weight, conv4_3_weight,
sizeof(float) * conv4_3_in_channel * conv4_3_out_channel *
conv4_3_kernel_size * conv4_3_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv4_3_bias, conv4_3_bias, sizeof(float) * conv4_3_out_channel,
cudaMemcpyHostToDevice);
//////////BLOCK 5/////////////////////////////////
cudaMemcpy(d_conv5_1_weight, conv5_1_weight,
sizeof(float) * conv5_1_in_channel * conv5_1_out_channel *
conv5_1_kernel_size * conv5_1_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv5_1_bias, conv5_1_bias, sizeof(float) * conv5_1_out_channel,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv5_2_weight, conv5_2_weight,
sizeof(float) * conv5_2_in_channel * conv5_2_out_channel *
conv5_2_kernel_size * conv5_2_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv5_2_bias, conv5_2_bias, sizeof(float) * conv5_2_out_channel,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv5_3_weight, conv5_3_weight,
sizeof(float) * conv5_3_in_channel * conv5_3_out_channel *
conv5_3_kernel_size * conv5_3_kernel_size,
cudaMemcpyHostToDevice);
cudaMemcpy(d_conv5_3_bias, conv5_3_bias, sizeof(float) * conv5_3_out_channel,
cudaMemcpyHostToDevice);
cudaMemcpy(d_fc1_weight, fc1_weight,
sizeof(float) * fc1_in_channel * fc1_out_channel,
cudaMemcpyHostToDevice);
cudaMemcpy(d_fc1_bias, fc1_bias, sizeof(float) * fc1_out_channel,
cudaMemcpyHostToDevice);
// copy input image
size_t image_size = batch * input_size * input_size * input_channel;
cudaMemcpy(d_image, image, image_size * sizeof(uint8_t),
cudaMemcpyHostToDevice);
}
void vgg16_cuda::classify(int* predict, int batch) {
// read logits back to cpu
cudaMemcpy(output, d_output, sizeof(float) * output_size * batch,
cudaMemcpyDeviceToHost);
// Softmax
softmax(output, predict, batch, output_size);
}
vgg16_cuda::~vgg16_cuda() {
cudaFree(d_conv1_1_weight);
cudaFree(d_conv1_2_weight);
cudaFree(d_conv2_1_weight);
cudaFree(d_conv2_2_weight);
cudaFree(d_conv3_1_weight);
cudaFree(d_conv3_2_weight);
cudaFree(d_conv3_3_weight);
cudaFree(d_conv4_1_weight);
cudaFree(d_conv4_2_weight);
cudaFree(d_conv4_3_weight);
cudaFree(d_conv5_1_weight);
cudaFree(d_conv5_2_weight);
cudaFree(d_conv5_3_weight);
cudaFree(d_conv1_1_bias);
cudaFree(d_conv1_2_bias);
cudaFree(d_conv2_1_bias);
cudaFree(d_conv2_2_bias);
cudaFree(d_conv3_1_bias);
cudaFree(d_conv3_2_bias);
cudaFree(d_conv3_3_bias);
cudaFree(d_conv4_1_bias);
cudaFree(d_conv4_2_bias);
cudaFree(d_conv4_3_bias);
cudaFree(d_conv5_1_bias);
cudaFree(d_conv5_2_bias);
cudaFree(d_conv5_3_bias);
cudaFree(d_fc1_weight);
cudaFree(d_fc1_bias);
cudaFree(d_image);
cudaFree(d_input);
cudaFree(d_input_padded);
cudaFree(d_C1_1_feature_map);
cudaFree(d_C1_1_feature_map_padded);
cudaFree(d_C1_2_feature_map);
cudaFree(d_S1_feature_map);
cudaFree(d_S1_feature_map_padded);
cudaFree(d_C2_1_feature_map);
cudaFree(d_C2_1_feature_map_padded);
cudaFree(d_C2_2_feature_map);
cudaFree(d_S2_feature_map);
cudaFree(d_S2_feature_map_padded);
cudaFree(d_C3_1_feature_map);
cudaFree(d_C3_1_feature_map_padded);
cudaFree(d_C3_2_feature_map);
cudaFree(d_C3_2_feature_map_padded);
cudaFree(d_C3_3_feature_map);
cudaFree(d_S3_feature_map);
cudaFree(d_S3_feature_map_padded);
cudaFree(d_C4_1_feature_map);
cudaFree(d_C4_1_feature_map_padded);
cudaFree(d_C4_2_feature_map);
cudaFree(d_C4_2_feature_map_padded);
cudaFree(d_C4_3_feature_map);
cudaFree(d_S4_feature_map);
cudaFree(d_S4_feature_map_padded);
cudaFree(d_C5_1_feature_map);
cudaFree(d_C5_1_feature_map_padded);
cudaFree(d_C5_2_feature_map);
cudaFree(d_C5_2_feature_map_padded);
cudaFree(d_C5_3_feature_map);
cudaFree(d_S5_feature_map);
cudaFree(d_output);
cudaFree(d_predict_cuda);
}
References
[1] Araujo, A., Norris, W., & Sim, J. (2019). Computing receptive fields of convolutional neural networks. Distill, 4(11), e21
[2] https://theaisummer.com/receptive-field/